
What does the ideal information environment look like?

I realized the other day that this one question can generate the entire field of open memetics, if you hold it in your mind and look at your world through it.

An “axiom” you might deduce from thinking through this is:
(1) if an open problem exists,
(2) and a solution for that problem is found,
→ then the solution will propagate to the relevant receivers
An open problem that remains unsolved therefore means one of two things:
(1) the problem is unsolved
(2) you are inside a noisy / hostile information environment
Most people have some experience of (2), especially if they’ve worked for a big corporation. They know the “information market” is not efficient, because known solutions are slow to propagate, or sometimes never make it1.
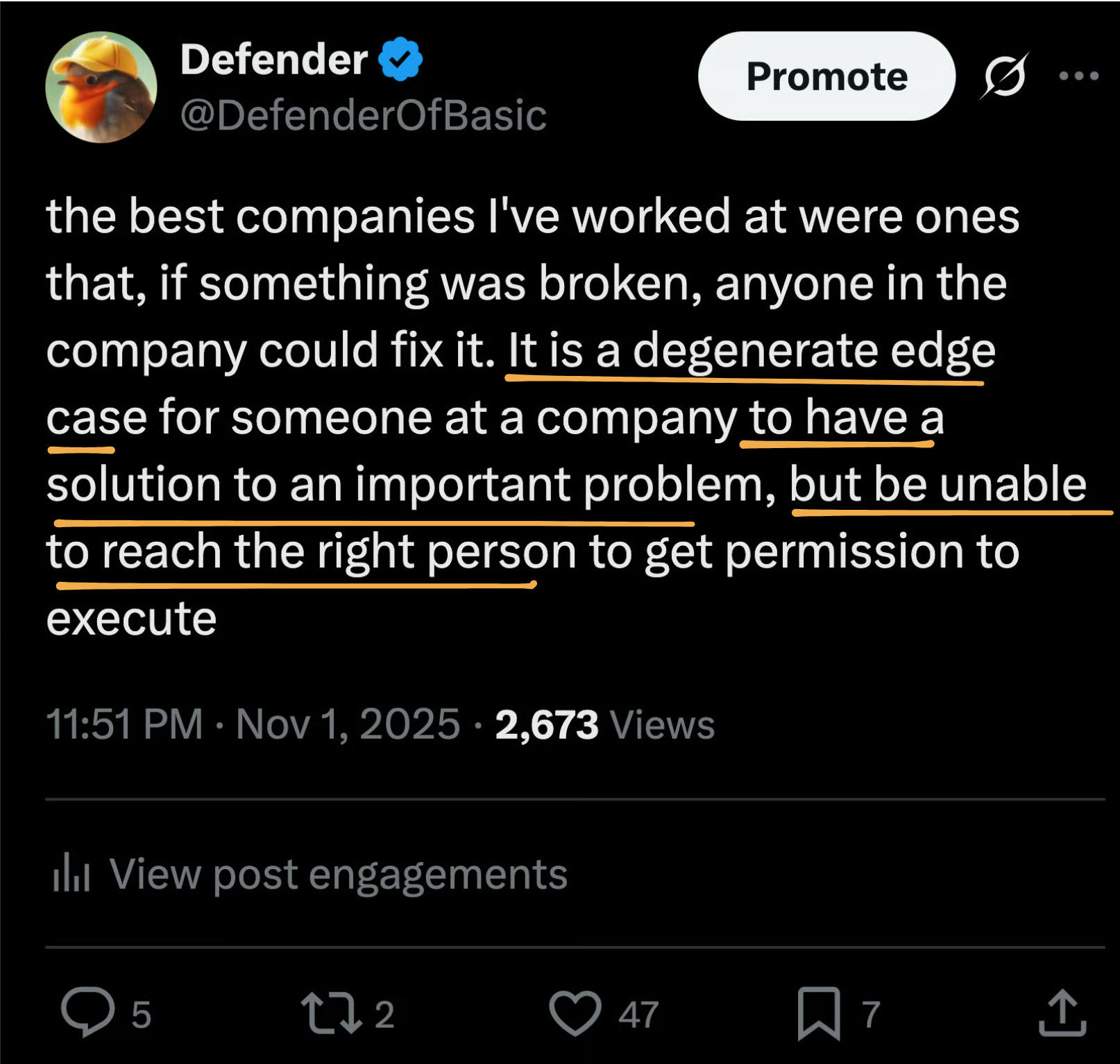
Do you see how this points towards empirical measurements of memetics?
If you are memetically observing a company, you find an unimplemented solution, you connect it to the relevant stakeholders, and the company executes it and makes a ton of money, then you have (1) solved a valuable problem (2) you have evidence of the health of this environment.
If you found a perfectly good solution just sitting there - there might be more. If you can understand the bottleneck for it reaching the right person, you can:
find more ideas like it and help them propagate
make a permanent fix to the memetic landscape so that any ideas like it in the future have an unblocked path
For example: it could be that the engineering team has no contact with the sales team. So if you setup a weekly meeting with the two managers that’d fix it2.
How do you get compensated for solving “information asymmetry bugs”?
This is one of the current open problems of the field. Someone who is selling you “solutions to information symmetry” (aka showing you valuable information that isn’t currently in your awareness) is a middleman that you need to trust. He has a perverse incentive to allow the environment to get worse, so that his work is more valuable. If he does his work very well, he makes himself obsolete.
We are working on fixing this in open memetics by (1) looking at ways that information asymmetry can be visible to the receiver, so you can compensate whoever is genuinely making it better (2) finding ways to monetize/compensate this work, so that more people are incentivized to do it (since it improves almost everything else - everything is downstream from the health of the information environment).
A frustrating bottleneck I’ve run into in advocating for open memetics is the “we live in a perfect information environment” fallacy
I tell people that this work matters because “there may be solutions to a lot of our open problems, but they’re just sitting there, and we’re pouring resources into trying to solve them, but they’ve already been solved & you aren’t aware of the solution”.
This sounds like a crazy claim - they say “if a solution existed to this obviously important problem, we’d know about it”. But from my POV, theirs is the crazy claim. What is this magical mechanism that you are assuming that will surface the information you need, when you need it?
They ask me, “if what you say is true, then prove it”. Now, if I do successfully surface a problem that is solved by connecting two unconnected networks, they see it as an outlier. “Ah, this is the information market working as expected!” - but that’s dumb, that solution was sitting there for months (or years!!!) before I unblocked it. The market is not efficient. We ARE the market. That it took years for someone ahead of their time to be recognized is NOT NORMAL nor inevitable. It’s a bug. It doesn’t have to be this way.
I believe this memetic learned helplessness exists only because these problems have been way too complicated to solve before. Paying too much attention to the flows of information propagation can lead to paranoia and spinning your wheels for nothing. But it doesn’t have to be this way either.
Open memetics is about working on these methods in public, and testing each other. We will create as a byproduct a lot of value, that will benefit a lot of people. Those people will make a lot of money, and we will capture a tiny fraction of it.
But that’s OK. Projects like Wikipedia, Open Street Map, and most open source infrastructure work exactly this way - they produce enormous value and they capture very little of it. But the alternative is worse for everyone. It’s a point of pride to be a contributor to Wikipedia, Open Street Map, or any kind of public infrastructure. And I think it can and will be a point of pride to contribute to open memetics.
As a reminder, if you haven’t seen it yet, we’ve started an Open Memetics github repo where we’re currently writing down “basic concepts” to coalesce into a shared language for the field. Don’t worry if you’re not on GitHub, you can contribute from wherever you are. Like Shadow Rebbe recently noticed a typo, DMed me, which I have fixed on his behalf and credited him3.
Important not to delude yourself here - you must be able to tell the difference between (1) YOU think a solution exists, but if you actually got to execute it, it would fail, or have costs that make the tradeoff not worth it (2) a solution actually is known
Many people dismiss this and assume that whatever the market is currently doing, it is the most efficient. But this is obviously wrong because - improvements are possible, they happen every single day. Engineers often fall into this mental trap of thinking that they could run the company better than their incompetent, non technical manager - but often the engineer can see clearly the tech pieces but NOT the other tradeoffs of the big picture.
But all that is to say: yes there’s a lot of pitfalls to finding truth here, but you CAN find truth here. And in the cases where you do have the truth, you can use that to test the information environment (see how long it takes for the solution to propagate, and observe that the solution does in fact improve outcomes)
I want to write a follow-up essay called “the CEO & the janitor conspire”, it’s about how a company can be setup to detect these information blockages. It is not enough to find & resolve each case as you find it. Because the whole point is that, there may exist things that you are NOT aware of. How can you measure that which is “outside of your awareness” ? You can’t, by definition!
But there is a trick around it. You can assume that something exists outside of your awareness, with properties XYZ (in this case, a solution to a company problem that isn’t bubbling up). You can then artificially construct that thing, inject it into the system, and see if it “bubbles up”. The CEO conspires with the janitor, feeds him information, sees if it reaches back.
This is almost like the biopsy thing doctors do (inject a “tracer” fluid to watch it go through your body), but for the information environment / egregore. This isn’t done very often because it feels like a hostile thing to test your employees this way - but even if everyone was good faith, that doesn’t imply that the information environment is perfect. If I receive information and I fail to propagate it upwards, letting me know that is GOOD for me - I get a better idea of what my superiors want to know.
One of the most beautiful things about open memetics is that it is the only scientific field where literally every human can make a valuable contribution. You are not outside the river of information - the river is made up of you & minds like yours. Your perspective, if not yet represented in OMI, is valuable. If it is already represented, then you can corroborate, or improve your own epistemology.
You growing your discernment & adopting the Open Memetics protocols helps good ideas propagate faster. We literally cannot do it without people choosing to cooperate and contribute.
> “we live in a perfect information environment” fallacy
Honey, even your brain isn’t a perfect information environment! If you can’t trust your thoughts and beliefs to be internally consistent, why would you expect everyone else to be?
Loved this. One of my favorite use cases for LLM’s is leveraging them for solved problems of this nature. They’re way better than web search at it and there’s a lot that can be built on top of them to make them even better at it, mostly (I think) by figuring out how to filter out fake non-solutions / bullshit in the training data.